Hadoop 에코 시스템을 구축하는 것을 CentOS에서 진행하고자 합니다.
김강원 저, 「실무로 배우는 빅데이터 기술」 책과 인터넷을 하여 설치 진행 방법을 작성합니다.
VirtualBox 설치법은 아래 글을 참고하시면 되겠습니다.
https://minhyeok-kimm.tistory.com/8
VirtualBox + Ubuntu 22.04.3 LTS 설치
프로그래밍이나 개발 등을 할 때 Linux 환경의 서버가 대다수인데, Windows 환경에서는 이를 경험해보고 구현해 보기 어렵습니다. 이를 간단하게 가상환경 구축으로 해결할 수 있는데, 이 방법에 대
minhyeok-kimm.tistory.com
1. Java 및 VirtualBox 설치
- 자세한 설치법은 위의 링크를 참고해주세요.
2. CentOS iso 파일 다운로드
- CentOS 페이지에서 iso 파일을 다운로드 받습니다. 아래 링크에서 바로 받으실 수 있으며, Stream 9 버전입니다.
https://www.centos.org/download/
3. VirtualBox 가상 머신을 생성합니다. 편의상 Server01로 명명하겠습니다.
- ISO 이미지를 선택하면 자동으로 종류 및 Subtype 등이 지정됩니다.

- 생성 후 네트워크 설정에서 어댑터 2를 활성화시킨 후 호스트 전용 어댑터로 지정합니다.

- CentOS 설치파일을 마운트시킵니다.

- 시작을 통해 CentOS를 설치합니다.

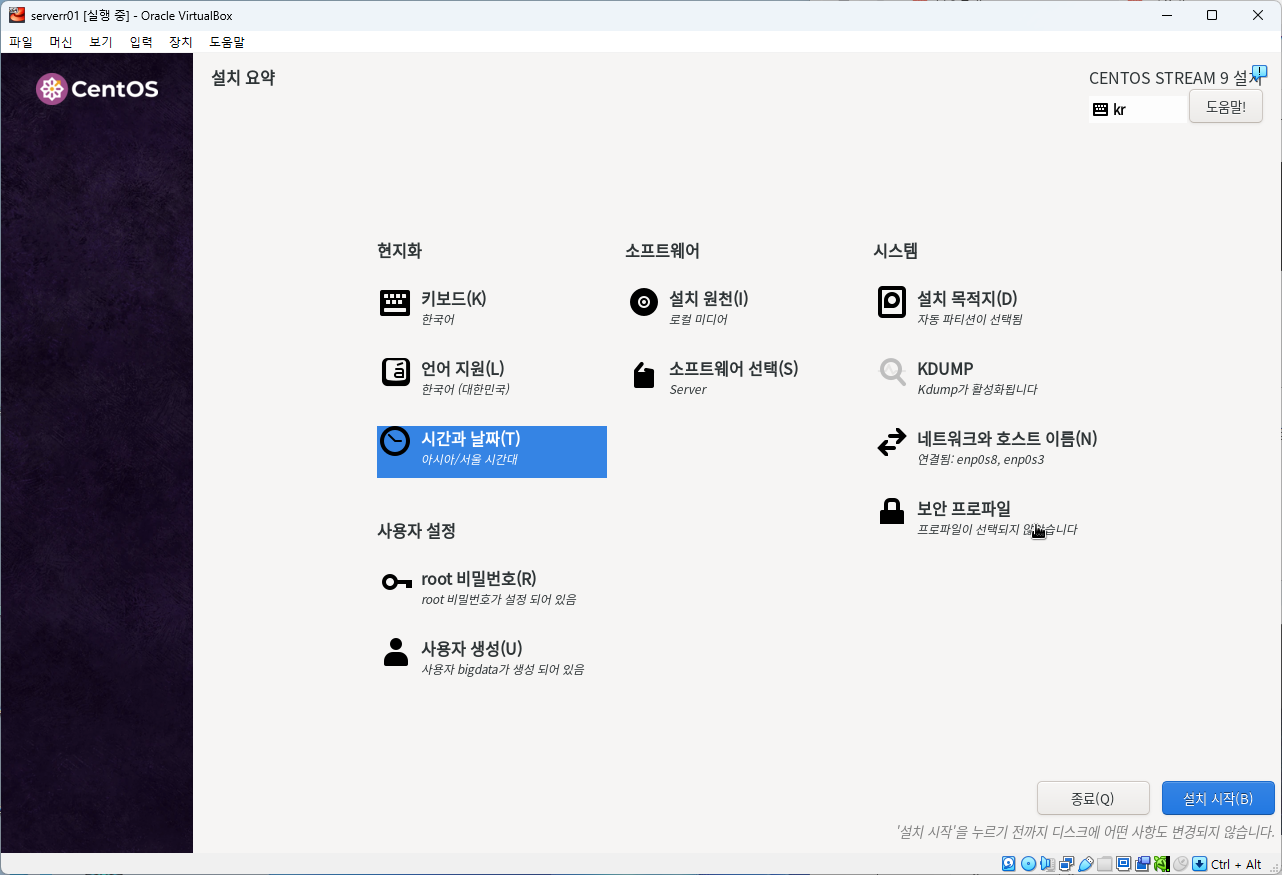
- 아래 내용과 같이 각종 세팅을 진행하였습니다.
1. Hostname: server01.hadoop.com
2. Root 암호: adminuser
3. 사용자명 및 암호: bigdata

4. CentOS 환경을 구성합니다.
1) 고정IP와 네트워크 설정을 위해 파일을 생성 후 내용을 입력합니다.
$ vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=(본인의 MAC 주소)
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.56.101
NETMASK=255.255.255.0
GATEWAY=192.168.56.1
NETWORK=192.168.56.0

- 여기서 HWADDR에 들어가는 각 가상머신의 MAC 주소는 가상머신 설정 > 네트워크 > 어댑터2에서 확인할 수 있는 주소값을 두 자리 숫자 단위로 잘라 ":"를 구분값으로 입력하여 넣습니다.

- 입력 완료 후 저장한 뒤 재시작을 진행, ifconfig 명령어를 통해 eth0 inet이 지정한 ip주소가 맞는지 확인합니다.

2) SSH 접속을 위한 패키지를 설치합니다. (수정) -> CentOS 9 버전에서는 해당 작업을 할 필요 없음.
$ yun install openssh*
$ service sshd restart
$ chkconfig sshd on
$ reboot
3) 외부 ssh 접속을 허용하기 위해 vi 편집기를 이용하여 파일을 수정합니다.
$ vi /etc/ssh/sshd_config
(수정할 부분)
# PermitRootLogin prohibit-password
(수정)
PermitRootLogin yes
:wq # 저장 후 종료
$ systemctl restart sshd
4) server01의 호스트 정보를 수정합니다.
$ vi /etc/hosts
(파일)
127.0.0.1 localhost server01
192.168.56.101 server01.hadoop.com server01
192.168.56.102 server02.hadoop.com server02
192.168.56.103 server03.hadoop.com server03
(저장 후 종료)
5) 아래 내용은 참고하는 책의 파일럿 프로그램에서 최적화한 설정을 실행하는 내용입니다.
$ vi /etc/selinux/config # config 파일에서 SELINUX를 "SELINUX=disabled"로 수정
$ service nftables stop # centos8부터는 iptables(X) nftables(O)
$ systemctl disable nftables # nftables 자동 시작 중지 명령
# chkconfig ip6tables off # CeotOS 9에서는 작동하지 않고 있음
$ sysctl -w vm.swappiness=100 # vm swappiness 사용 제어 설정
$ vi /etc/sysctl.conf # "vm.swappiness=100" 설정 추가
$ vi /etc/rc.local # 아래 명령어를 추가
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
$ vi /etc/security/limits.conf # 아래 파일 디스크립터 설정을 추가
root soft nofile 65536
root hard nofile 65536
* soft nofile 65536
* hard nofile 65536
root soft nproc 32768
root hard nproc 32768
* soft nproc 32768
* hard nproc 32768
$ reboot # 서버 리부팅
5. 다중 서버 생성
1) server01 가상머신의 전원을 끈 후 3대의 서버를 만들기 위해 복제를 진행합니다.



2) 복제가 완료된 후 처음 설정했던 거소가 같이 네트워크의 MAC 주소를 확인한 뒤 server02를 부팅시켜 들어갑니다.
3) 처음 설정한 root 계정으로 접속합니다.
4) 처음 지정한 server01의 네트워크 설정값으로 되어 있으므로, MAC 정보와 고정 IP를 수정합니다.
$ vi /etc/sysconfig/network-scripts/ifcfg-eth0
HWADDR(MAC 주소) 와 IPADDR(IP 주소)를 각각 server02에 맞게 수정합니다.

5) 재부팅 후 ifconfig 명령어를 통해 잘 수정되었는지 확인합니다.
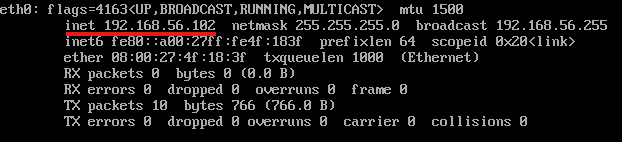
6) 복제를 한 관계로 host 정보 및 hostname 정보를 수정합니다. hostname 정보 수정 및 hostname을 수정합니다.
$ vi /etc/hosts
127.0.0.1 localhost server02 # server01을 server02로 수정
$ hostnamectl set-hostname server02.hadoop.com
$ hostname
# server02.hadoop.com
7) 사양이 어느정도 되는 분들의 경우 3개, 그렇지 않은 경우 2개로 서버 생성을 마칩니다. 저의 경우 데스크톱에는 3개, 노트북에는 2개의 서버를 생성하여 환경 조성을 하였습니다.
여기까지 다중 서버를 만들었고, 이 위에 하둡 에코 시스템을 올려볼 예정입니다.
'Hadoop' 카테고리의 다른 글
| Hadoop 기초 (1) (0) | 2024.11.14 |
|---|